Difference between revisions of "Bioinformatics Introduction Function"
(Created page with "<div id="BIO"> <div class="b1"> Function<br /> </div> <table style="width:100%;"><tr> <td style="height:30px; align:center; vertical-align:middle;">[[Bioinformatics_Introduct...") |
m |
||
| (2 intermediate revisions by the same user not shown) | |||
| Line 12: | Line 12: | ||
</tr></table> | </tr></table> | ||
| + | {{Vspace}} | ||
| + | {{Vspace}} | ||
__TOC__ | __TOC__ | ||
| + | {{Vspace}} | ||
| + | |||
| + | |||
| + | ==The Function Unit== | ||
| + | |||
| + | This Unit is part of a brief introduction to bioinformatics. The material is more or less interleaved with the <code>Function.R</code> Project File which is part of the RStudio project associated with this material. Refer to the course/workshop page for installation instructions. | ||
| + | |||
| + | The unit covers expression analysis, introduces you to the STRING database of functional interactions, and explores graph analysis with the iGraph '''R''' package. | ||
| + | |||
| + | {{Vspace}} | ||
| + | |||
| + | {{Vspace}} | ||
==Expression Analysis== | ==Expression Analysis== | ||
| Line 24: | Line 38: | ||
'''Microarray technology''' — the quantitative, sequence-specific hybridization of labelled nucleotides in chip-format — was the first domain of "high-throughput biology". Today, it has largely been replaced by {{WP|RNA-Seq|'''RNA-seq'''}}: quantification of transcribed mRNA by high-throughput sequencing and mapping reads to genes. Quantifying gene expression levels in a tissue-, development-, or response-specific way has yielded detailed insight into cellular function at the molecular level, with recent results of single-cell sequencing experiments adding a new level of precision. But not all transcripts are mapped to genes: we increasingly realize that the transcriptome is not merely a passive buffer of expressed information on its way to be translated into proteins, but contains multiple levels of complex, regulation through hybridization of small nuclear RNAs<ref>{{#pmid: 25565024}} {{#pmid: 21798102}}</ref>. | '''Microarray technology''' — the quantitative, sequence-specific hybridization of labelled nucleotides in chip-format — was the first domain of "high-throughput biology". Today, it has largely been replaced by {{WP|RNA-Seq|'''RNA-seq'''}}: quantification of transcribed mRNA by high-throughput sequencing and mapping reads to genes. Quantifying gene expression levels in a tissue-, development-, or response-specific way has yielded detailed insight into cellular function at the molecular level, with recent results of single-cell sequencing experiments adding a new level of precision. But not all transcripts are mapped to genes: we increasingly realize that the transcriptome is not merely a passive buffer of expressed information on its way to be translated into proteins, but contains multiple levels of complex, regulation through hybridization of small nuclear RNAs<ref>{{#pmid: 25565024}} {{#pmid: 21798102}}</ref>. | ||
| − | In this | + | In this unit, we will look at differential expression of Mbp1 and its target genes. |
| + | {{Vspace}} | ||
| − | + | ===GEO2R=== | |
| − | |||
| − | ==GEO2R== | ||
<section begin=exercises /> | <section begin=exercises /> | ||
| Line 66: | Line 79: | ||
# Recalculate the '''Top 250''' differentially expressed genes (you might have to refresh the page to get the "Top 250" button back.) Which of the "known" MBF targets are now contained in the set? What about Mbp1 and Swi6? | # Recalculate the '''Top 250''' differentially expressed genes (you might have to refresh the page to get the "Top 250" button back.) Which of the "known" MBF targets are now contained in the set? What about Mbp1 and Swi6? | ||
# Finally: Let's compare the expression profiles for Mbp1, Swi6 and Swi4. It is not obvious that transcription factors are themselves under '''transcriptional''' control, as opposed to being expressed at a basal level and ''activated'' by phosporylation or ligand binding. In a new page, navigate to the [http://www.ncbi.nlm.nih.gov/geoprofiles '''Geo profiles'''] page and enter <code>(Mbp1 OR Swi6 OR Swi4 OR Nrm1 OR Cln1 OR Clb6 OR Act1 OR Alg9) AND GSE3635</code> (Nrm1, Cln1, and Clb6 are Mbp1 target genes. Act1 and Alg9 are beta-Actin and mannosyltransferase, these are often used as "housekeeping genes, i.e. genes with condition-independent expression levels, especially for qPCR studies - although Alg9 is also an Mbp1 target. We include them here as negative controls. CGSE3635 is the ID of the GEO data set we have just studied). You could have got similar results in the '''Profile graph''' tab of the GEO2R page. What do you find? What does this tell you? Would this information allow you to define groups that are even better suited for finding cyclically expressed genes? | # Finally: Let's compare the expression profiles for Mbp1, Swi6 and Swi4. It is not obvious that transcription factors are themselves under '''transcriptional''' control, as opposed to being expressed at a basal level and ''activated'' by phosporylation or ligand binding. In a new page, navigate to the [http://www.ncbi.nlm.nih.gov/geoprofiles '''Geo profiles'''] page and enter <code>(Mbp1 OR Swi6 OR Swi4 OR Nrm1 OR Cln1 OR Clb6 OR Act1 OR Alg9) AND GSE3635</code> (Nrm1, Cln1, and Clb6 are Mbp1 target genes. Act1 and Alg9 are beta-Actin and mannosyltransferase, these are often used as "housekeeping genes, i.e. genes with condition-independent expression levels, especially for qPCR studies - although Alg9 is also an Mbp1 target. We include them here as negative controls. CGSE3635 is the ID of the GEO data set we have just studied). You could have got similar results in the '''Profile graph''' tab of the GEO2R page. What do you find? What does this tell you? Would this information allow you to define groups that are even better suited for finding cyclically expressed genes? | ||
| − | # Click on the profile graph for Mbp1 and print out the page. | + | # Click on the profile graph for Mbp1 and print out the page. I may ask you to hand in this page for credit in the course. With a red pen, '''in one sentence''' describe the evidence you find '''on that page''' that allows us to conclude '''whether or not''' Mbp1 is a cell-cycle gene. You'll probably want to think for a moment what this question really means, how a cell-cycle gene could be defined, and what can be considered "evidence", before you write. |
<!-- | <!-- | ||
* Finally, review the '''R''' script for the GEO2R analysis in the '''R script''' tab. This code will run on your machine and make the expression analysis available. Once the datasets are loaded and prepared, you could - for example - perform a "real" time series analysis, calculate correlation coefficients with an idealized sine wave, or search for genes that are '''co-regulated''' with your genes of interest. | * Finally, review the '''R''' script for the GEO2R analysis in the '''R script''' tab. This code will run on your machine and make the expression analysis available. Once the datasets are loaded and prepared, you could - for example - perform a "real" time series analysis, calculate correlation coefficients with an idealized sine wave, or search for genes that are '''co-regulated''' with your genes of interest. | ||
| Line 74: | Line 87: | ||
| − | + | {{Vspace}} | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | {{ | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | }} | ||
| − | |||
{{Vspace}} | {{Vspace}} | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
==Protein-Protein Interactions== | ==Protein-Protein Interactions== | ||
| Line 126: | Line 95: | ||
{{task|1= | {{task|1= | ||
| − | * | + | * Study these lecture notes that are relevant for this unit <span class="PDFlink">[http://steipe.biochemistry.utoronto.ca/abc/CourseMaterials/BCH441/11-Interactions_LectureNotes.pdf Week 11: Annotated Notes <small>(PDF 12.2 MB)</small>]</span>. |
| − | * For a useful overview of graph-theory concepts | + | * For a useful overview of graph-theory concepts, please read: |
{{#pmid: 21527005}} | {{#pmid: 21527005}} | ||
| − | |||
}} | }} | ||
| Line 138: | Line 106: | ||
{{Vspace}} | {{Vspace}} | ||
| − | ==Data Sources== | + | ===Data Sources=== |
| Line 145: | Line 113: | ||
Currently, likely the best integrated protein-protein interaction database is [http://www.ebi.ac.uk/intact/ '''IntAct'''], at the EBI, which besides curating interactions from the literature hosts interactions from the IMEx consortium, an extensive data-sharing agreement between a number of general and specialized source databases. | Currently, likely the best integrated protein-protein interaction database is [http://www.ebi.ac.uk/intact/ '''IntAct'''], at the EBI, which besides curating interactions from the literature hosts interactions from the IMEx consortium, an extensive data-sharing agreement between a number of general and specialized source databases. | ||
| − | {{ | + | {{Vspace}} |
{{task|1= | {{task|1= | ||
| Line 161: | Line 129: | ||
{{Vspace}} | {{Vspace}} | ||
| − | + | ===Interaction data visualization and analysis=== | |
| − | == | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
{{Vspace}} | {{Vspace}} | ||
| Line 198: | Line 146: | ||
| − | {{ | + | {{Vspace}} |
| Line 223: | Line 171: | ||
}} | }} | ||
| − | In summary, | + | In summary, STRING is a convincingly well built tool to explore functional relationships between proteins. |
| − | {{ | + | {{Vspace}} |
| + | {{Vspace}} | ||
| − | + | ==Working with biological graphs in R== | |
| − | |||
| − | |||
| − | == | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
{{task|1= | {{task|1= | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| + | * Open RStudio. | ||
| + | * Choose File → Recent Projects → R-Exercise_Bioinformatics. | ||
| + | * Pull the latest version of the project repository from GitHub. | ||
| + | * type <code>init()</code> | ||
| + | * Open the file <code>Function.R</code> and work through the entire tutorial. | ||
| − | + | * At the end of the tutorial, you are being asked to print '''R''' code and data on a sheet of paper. I may ask you to hand this in for credit later in the course. | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
}} | }} | ||
| + | {{Vspace}} | ||
| − | + | {{Vspace}} | |
| − | + | == Links and resources == | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| + | {{#pmid: 23193258}} | ||
| + | {{#pmid: 25392420}} | ||
| + | {{Vspace}} | ||
| + | {{#pmid: 21527005}} | ||
Latest revision as of 13:33, 9 January 2017
Function
| Data | Sequence | Structure | Phylogeny | Function |
Contents
The Function Unit
This Unit is part of a brief introduction to bioinformatics. The material is more or less interleaved with the Function.R Project File which is part of the RStudio project associated with this material. Refer to the course/workshop page for installation instructions.
The unit covers expression analysis, introduces you to the STRING database of functional interactions, and explores graph analysis with the iGraph R package.
Expression Analysis
The transcriptome is the set of a cell's mRNA molecules. The transcriptome originates from the genome, mostly, that is, and it results in the proteome, again: mostly. RNA that is transcribed from the genome is not yet fit for translation but must be processed: splicing is ubiquitous[1] and in addition RNA editing has been encountered in many species. Some authors therefore refer to the exome—the set of transcribed exons— to indicate the actual coding sequence.
Microarray technology — the quantitative, sequence-specific hybridization of labelled nucleotides in chip-format — was the first domain of "high-throughput biology". Today, it has largely been replaced by RNA-seq: quantification of transcribed mRNA by high-throughput sequencing and mapping reads to genes. Quantifying gene expression levels in a tissue-, development-, or response-specific way has yielded detailed insight into cellular function at the molecular level, with recent results of single-cell sequencing experiments adding a new level of precision. But not all transcripts are mapped to genes: we increasingly realize that the transcriptome is not merely a passive buffer of expressed information on its way to be translated into proteins, but contains multiple levels of complex, regulation through hybridization of small nuclear RNAs[2].
In this unit, we will look at differential expression of Mbp1 and its target genes.
GEO2R
In this exercise we will use the analysis facilities of the GEO database at the NCBI.
Task:
- First, we will search for relevant data sets on GEO, the NCBI's database for expression data.
- Navigate to the entry page for GEO data sets].
- Enter the following query in the usual Entrez query format:
"cell cycle"[ti] AND "saccharomyces cerevisiae"[organism]. - You should get two datasets among the top hits that analyze wild-type yeast (W303a cells) across two cell-cycles after release from alpha-factor arrest. Choose the experiment with lower resolution (13 samples).
- On the linked GEO DataSet Browser page, follow the link to the Accession Viewer page: the "Reference series".
- Read about the experiment and samples, then follow the link to analyze with GEO2R
- View the GEO2R video tutorial on youtube.
- Now proceed to apply this to the yeast cell-cycle study
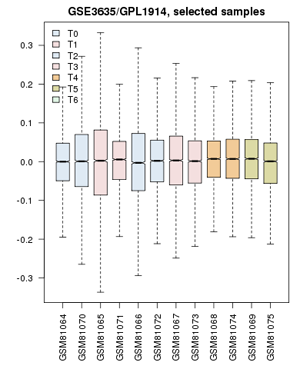 Value distribution for the yeast cell-cycle experiment GSE3635. Experiments are grouped approximately into equivalent time-points on a cell cycle.
Value distribution for the yeast cell-cycle experiment GSE3635. Experiments are grouped approximately into equivalent time-points on a cell cycle.

- Define groups: the associated publication shows us that one cell-cycle takes pretty exactly 60 minutes. Create timepoints T0, T1, T2, ... T5. Then associate the 0 and 60 min. sample with "T0"; 10 and 70 minutes get grouped as "T1"; 20 and 80 minutes are T2, etc. up to T5. The final sample does not get assigned.
- Confirm that the Value distributions are unbiased by accessing the value distribution tab - overall, in such experiments, the bulk of the expression values should not change and thus means and quantiles of the expression levels should be about the same.
- Your distribution should look like the image on the right: properly grouped into six categories, and unbiased regarding absolute expression levels and trends.
- Look for differentially expressed genes: open the GEO2R tab and click on Top 250.
- Analyze the results.
- Examine the top hits. Click on a few of the gene names in the Gene.symbol column to view the expression profiles that tell you why the genes were found to be differentially expressed. What do you think? Is this what you would have expected for genes' responses to the cell-cycle? What seems to be the algorithm's notion of what "differentially expressed" means?
- Look for expected genes. Here are a few genes that are known to be differentially expressed in the cell-cycle as target genes of the MBF complex:
DSE1,DSE2,ERF3,HTA2,HTB2, andGAS3. But what about the MBD complex proteins themselves: Mbp1 and Swi6?
The notion of "differential expression" and "cell-cycle dependent expression" do not overlap completely. Significant differential expression is mathematically determined for genes that have low variance within groups and large differences between groups. This algorithm has no notion of any expectation you might have about the shape of the expression profile. All it finds are genes for which differential expression between some groups is statistically supported. The algorithm returns the top 250 of those. Consistency within groups is very important, while we intuitively might be giving more weight to conformance to our expectations of a cyclical pattern.
Let's see if we can group our time points differently to enhance the contrast between expression levels for cyclically expressed genes. Let's define only two groups: one set before and between the two cycles, one set at the peaks - and we'll omit some of the intermediate values.
- Remove all of your groups and define two groups only. Call them "A" and "B".
- Assign samples for T = 0 min, 10, 60 and 70 min. to the "A" group. Assign sets 30, 40, 90, and 100 to the "B" group.
- Recalculate the Top 250 differentially expressed genes (you might have to refresh the page to get the "Top 250" button back.) Which of the "known" MBF targets are now contained in the set? What about Mbp1 and Swi6?
- Finally: Let's compare the expression profiles for Mbp1, Swi6 and Swi4. It is not obvious that transcription factors are themselves under transcriptional control, as opposed to being expressed at a basal level and activated by phosporylation or ligand binding. In a new page, navigate to the Geo profiles page and enter
(Mbp1 OR Swi6 OR Swi4 OR Nrm1 OR Cln1 OR Clb6 OR Act1 OR Alg9) AND GSE3635(Nrm1, Cln1, and Clb6 are Mbp1 target genes. Act1 and Alg9 are beta-Actin and mannosyltransferase, these are often used as "housekeeping genes, i.e. genes with condition-independent expression levels, especially for qPCR studies - although Alg9 is also an Mbp1 target. We include them here as negative controls. CGSE3635 is the ID of the GEO data set we have just studied). You could have got similar results in the Profile graph tab of the GEO2R page. What do you find? What does this tell you? Would this information allow you to define groups that are even better suited for finding cyclically expressed genes? - Click on the profile graph for Mbp1 and print out the page. I may ask you to hand in this page for credit in the course. With a red pen, in one sentence describe the evidence you find on that page that allows us to conclude whether or not Mbp1 is a cell-cycle gene. You'll probably want to think for a moment what this question really means, how a cell-cycle gene could be defined, and what can be considered "evidence", before you write.
Protein-Protein Interactions
Task:
- Study these lecture notes that are relevant for this unit Week 11: Annotated Notes (PDF 12.2 MB).
- For a useful overview of graph-theory concepts, please read:
| Pavlopoulos et al. (2011) Using graph theory to analyze biological networks. BioData Min 4:10. (pmid: 21527005) |
|
[ PubMed ] [ DOI ] Understanding complex systems often requires a bottom-up analysis towards a systems biology approach. The need to investigate a system, not only as individual components but as a whole, emerges. This can be done by examining the elementary constituents individually and then how these are connected. The myriad components of a system and their interactions are best characterized as networks and they are mainly represented as graphs where thousands of nodes are connected with thousands of vertices. In this article we demonstrate approaches, models and methods from the graph theory universe and we discuss ways in which they can be used to reveal hidden properties and features of a network. This network profiling combined with knowledge extraction will help us to better understand the biological significance of the system. |
Data Sources
Interaction databases have similar problems as sequence databases: the need for standards for abstracting biological concepts into computable objects, data integrity, search and retrieval, and the metrics of comparison. There is however an added complication: interactions are rarely all-or-none, and the high-throughput experimental methods have large false-positive and false-negative rates. This makes it necessary to define confidence scores for interactions. On top of experimental methods, there are also a variety of methods for computational interaction prediction. However, even though the "gold standard" are careful, small-scale laboratory experiments, different curated efforts on the same experimental publication usually lead to different results - with as little as 42% overlap between databases being reported.
Currently, likely the best integrated protein-protein interaction database is IntAct, at the EBI, which besides curating interactions from the literature hosts interactions from the IMEx consortium, an extensive data-sharing agreement between a number of general and specialized source databases.
Task:
- Access IntAct and enter the UniProt ID for yeast Mbp1 P39678.
- Click on the "Graph" tab to load a network graph.
- Switch "Merge edges" off to show the reported edges for this interaction individually. Which protein pair has the most interactions? Does this make sense?
But then what?
If you are like me, you would now like to be able to link expression profiles, information about known complexes, GO annotations, knock-out phenotypes etc. etc. Too bad.
Interaction data visualization and analysis
If you work a lot with interaction networks, sooner or later you will come across Cytoscape. It is more or less the standard among "professional" systems biologists. But it is not an online tool.
Task:
- Navigate to the Cytoscape homepage and inform yourself what the program does and how to install it. There are many tutorials online available. But this is software that needs to be downloaded, and installed and it definitively has a learning curve.
The state of integrated online interaction viewers these days could be improved. Have a look at this article that discusses the gap between what one would need to do, and what is offered:
| Jeanquartier et al. (2015) Integrated web visualizations for protein-protein interaction databases. BMC Bioinformatics 16:195. (pmid: 26077899) |
|
[ PubMed ] [ DOI ] BACKGROUND: Understanding living systems is crucial for curing diseases. To achieve this task we have to understand biological networks based on protein-protein interactions. Bioinformatics has come up with a great amount of databases and tools that support analysts in exploring protein-protein interactions on an integrated level for knowledge discovery. They provide predictions and correlations, indicate possibilities for future experimental research and fill the gaps to complete the picture of biochemical processes. There are numerous and huge databases of protein-protein interactions used to gain insights into answering some of the many questions of systems biology. Many computational resources integrate interaction data with additional information on molecular background. However, the vast number of diverse Bioinformatics resources poses an obstacle to the goal of understanding. We present a survey of databases that enable the visual analysis of protein networks. RESULTS: We selected M=10 out of N=53 resources supporting visualization, and we tested against the following set of criteria: interoperability, data integration, quantity of possible interactions, data visualization quality and data coverage. The study reveals differences in usability, visualization features and quality as well as the quantity of interactions. StringDB is the recommended first choice. CPDB presents a comprehensive dataset and IntAct lets the user change the network layout. A comprehensive comparison table is available via web. The supplementary table can be accessed on http://tinyurl.com/PPI-DB-Comparison-2015. CONCLUSIONS: Only some web resources featuring graph visualization can be successfully applied to interactive visual analysis of protein-protein interaction. Study results underline the necessity for further enhancements of visualization integration in biochemical analysis tools. Identified challenges are data comprehensiveness, confidence, interactive feature and visualization maturing. |
The online resource that comes out as the best is the one at the String database.
Task:
- Navigate to the String database and search for saccharomyces cerevisiae Mbp1 interactors.
- Visualize the network. Add a few proteins by clicking the (+) button a two or three times.
- Click on a node to get a synopsis of its function.
- Explore the "confidence", "evidence" and "actions" networks for the retrieved interactors.
- Not all interacting proteins are also predicted to have a functional relationship with Mbp1. Do you agree?
- Explore the clustering and layout options. Do you understand what they do?
- Explore the Views on
- Neighborhood (not relevant for our query though)
- Fusion (also not relevant for our query)
- Occurence
- Coexpression
- Experiments
- Database, and
- Textmining
Each of these are methods for predicting functional relationships. Figure out how each one contributes to evidence of a functional interaction between Mbp1 and its predicted functional partners. I find the Occurrence view a unique and intriguing tool: visualizing in which organisms groups of genes are either all absent or all present allows to quickly establish functional clusters.
In summary, STRING is a convincingly well built tool to explore functional relationships between proteins.
Working with biological graphs in R
Task:
- Open RStudio.
- Choose File → Recent Projects → R-Exercise_Bioinformatics.
- Pull the latest version of the project repository from GitHub.
- type
init() - Open the file
Function.Rand work through the entire tutorial.
- At the end of the tutorial, you are being asked to print R code and data on a sheet of paper. I may ask you to hand this in for credit later in the course.
Links and resources
| Barrett et al. (2013) NCBI GEO: archive for functional genomics data sets--update. Nucleic Acids Res 41:D991-5. (pmid: 23193258) |
|
[ PubMed ] [ DOI ] The Gene Expression Omnibus (GEO, http://www.ncbi.nlm.nih.gov/geo/) is an international public repository for high-throughput microarray and next-generation sequence functional genomic data sets submitted by the research community. The resource supports archiving of raw data, processed data and metadata which are indexed, cross-linked and searchable. All data are freely available for download in a variety of formats. GEO also provides several web-based tools and strategies to assist users to query, analyse and visualize data. This article reports current status and recent database developments, including the release of GEO2R, an R-based web application that helps users analyse GEO data. |
| Okamura et al. (2015) COXPRESdb in 2015: coexpression database for animal species by DNA-microarray and RNAseq-based expression data with multiple quality assessment systems. Nucleic Acids Res 43:D82-6. (pmid: 25392420) |
|
[ PubMed ] [ DOI ] The COXPRESdb (http://coxpresdb.jp) provides gene coexpression relationships for animal species. Here, we report the updates of the database, mainly focusing on the following two points. For the first point, we added RNAseq-based gene coexpression data for three species (human, mouse and fly), and largely increased the number of microarray experiments to nine species. The increase of the number of expression data with multiple platforms could enhance the reliability of coexpression data. For the second point, we refined the data assessment procedures, for each coexpressed gene list and for the total performance of a platform. The assessment of coexpressed gene list now uses more reasonable P-values derived from platform-specific null distribution. These developments greatly reduced pseudo-predictions for directly associated genes, thus expanding the reliability of coexpression data to design new experiments and to discuss experimental results. |
| Pavlopoulos et al. (2011) Using graph theory to analyze biological networks. BioData Min 4:10. (pmid: 21527005) |
|
[ PubMed ] [ DOI ] Understanding complex systems often requires a bottom-up analysis towards a systems biology approach. The need to investigate a system, not only as individual components but as a whole, emerges. This can be done by examining the elementary constituents individually and then how these are connected. The myriad components of a system and their interactions are best characterized as networks and they are mainly represented as graphs where thousands of nodes are connected with thousands of vertices. In this article we demonstrate approaches, models and methods from the graph theory universe and we discuss ways in which they can be used to reveal hidden properties and features of a network. This network profiling combined with knowledge extraction will help us to better understand the biological significance of the system. |
Footnotes and references
- ↑ Strictly speaking, splicing is an eukaryotic achievement, however there are examples of splicing in prokaryotes as well.
- ↑
(2015) The noncoding explosion. Nat Struct Mol Biol 22:1. (pmid: 25565024) Jarvis & Robertson (2011) The noncoding universe. BMC Biol 9:52. (pmid: 21798102)
Ask, if things don't work for you!
- If anything about this page is not clear to you, please ask on the mailing list. You can be certain that others will have had similar problems. Success comes from joining the conversation.
- Do consider how to ask your questions so that a meaningful answer is possible:
- Review Netiquette for the course mailing list.
- Read How to create a Minimal, Complete, and Verifiable example on stackoverflow and ...
- How to make a great R reproducible example.
| Data | Sequence | Structure | Phylogeny | Function |