Amino Acid Exam Questions
Jump to navigation
Jump to search
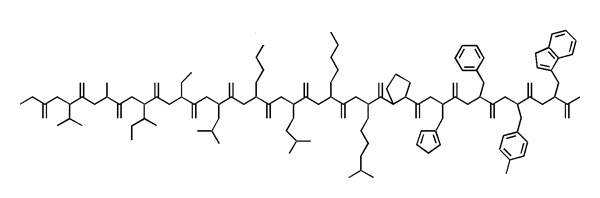
- Of all data abstractions in bioinformatics, the one-letter amino acid code is the most important one. Whether we are evaluating multiple sequence alignments, database searches or mutational studies, this all requires a confident understanding of the physicochemical nature of the residues we are considering and of course knowing which letters correspond to which amino acids.
2002

This sketch shows the bonding topologies of amino acids in a polypeptide. Only bonds between non-hydrogen atoms are shown but single and double bonds are distinguished. This identification task is similar to inferring the sequence from a wireframe structural image.
- Write the sequence of this polypeptide into your exam booklet in one-letter code. Where the sidechains are ambiguous, write all possible one letter codes for the residue in square brackets. Annotate residues that are > 80 % charged at physiological pH with a "+" or "-".
- Example:
AB+CD[EFG]HIJ[KL]M-N-OPQ